博亚体育 2nm芯片逆境

公众号谨记加星标⭐️,第一时候看推送不会错过。
在 2 纳米及以下工艺水平,摩尔定律意味着更多,但更多也意味着更少。
表面上,在光刻胶大小的芯片上集成的晶体管越多,芯片处理数据以及在存储器和芯片之间走动传输数据的速率就越快。但表面与现实正在出现偏差。
从历史上看,已毕这一标的的最好步调是缩小晶体管、导线和存储单位的尺寸。但在 2 纳米及以下制程工艺下,这种步调面对严峻挑战。导线极端细,导致 RC 蔓延成为一个要紧难题。动作缓存主要技能的 SRAM 尺寸缩小,在数字逻辑电路的缩小方面远远逾期。这反过来又限度了单个光罩大小的芯片上可容纳的存储容量。此外,由于工艺偏差,在晶圆厂中已毕沟通的良率也变得愈加困难,因为工艺偏差可能出现时数百以致数千个插入点以及制造过程中使用的数十种器用上。
任何制造工艺都存在一定进程的偏差,但在2纳米制程中,偏差的进程过头成因都在增多。由于金属层和衬底越来越薄,容易发生翘曲,导致凸点无法王人备聚合;此外,为确保芯片可靠性而需要的数十说念工序也可能迟滞或损坏脆弱的互聚合构或材料。芯片制造开导自己存在偏差,原材料和晶圆也雷同如斯。其效果是,天然芯片上的晶体管和互连数目更多,但纰谬率也更高。本钱上升,良率下落。
Synopsys工程副总裁 Abhijeet Chakraborty 示意:“东说念主们渴望尺寸缩小后,器件性能会更快、功耗更低、晶体管密度更高。但挑战在于能否已毕这些标的。能否已毕性能晋升 10% 到 15%,功耗裁汰 20% 到 30%?对于好多看护每瓦性能和晶体管密度的应用来说,更低的功耗极具引诱力。但能否作念到这一丝呢?这其中蕴含着诸多挑战和考量。试验应用中,良率和可制造性都面对着诸多挑战。”
制造工艺是一个不绝完善的过程。跟着时候的推移,工艺不绝矫正,使得代工场能够放宽那些为每项前沿工艺预留裕量的严格想象规定,也使得EDA和开导供应商能够针对每项工艺制定相应的规定和例外情况。最初,只是是让这些先进节点想象能够平常运行自己即是一项工程豪举,而早期版块时常是针对最坏情况想象的,其中包含冗余晶体管、互连线以及富余的内置自测试功能,以便在必要时重新路由数据和处理过程。
但这种利润空间会占用难得的面积资源,限度性能和能源方面的投资报酬。
“在2nm和18A工艺中,裕量已成为最受诟病的资源之一,” proteanTecs首席技能官Evelyn Landman示意。“裕量必须足以应酬工艺偏差、热效应和环境影响、使命负载压力、潜在纰谬以及老化等问题。将扫数这些身分汇总到一个单一的最坏情况保护带中已不再可行。静态保护带会就义性能和功耗,而况仍然无法抗拒试验应用环境中的各式挑战。惟一可捏续的步调是径直测量保护带,即在试验使命负载下,以高障翳率及时监测时序裕量,并在居品质命周期内捏续处分。其中枢想想是径直监测时序裕量,而不是通过迤逦步调。”
跟着工艺的隆重,不错在保捏可接受良率的前提下减少裕量。但对于5nm以下的每个新节点,尤其是2nm及以下节点,已毕这一标的所需的时候越来越长。尽管16/14埃节点正在研发中,10埃(相称于1nm)节点的研发使命也已启动,但从5nm之后的每个节点开动,达到足以温和大限制量产良率要求的量产所需的时候都在延长。
英特尔逻辑技能副总裁兼总司理 Ben Sell 示意:“14A 之后,下一个清贫的制程节点是 10A。咱们照旧在研发这个节点了,但节点称号自己并不清贫,清贫的是它能否温和客户的需求。咱们时常会先细则一个基础节点。咱们会为少数几个最清贫的客户界说一个基础节点。咱们称这些客户为‘界说型客户’,节点即是凭据他们的需求来界说的。淌若这个节点温和了咱们主要客户的需求,那么在与更多客户相助时,咱们可能会对这个节点进行一些修改。比如增多几层金属层,或者进行一些小的蜕变,以温和特假寓品的需求。但这些蜕变幅度相对较小,因为咱们但愿确保扫数已开发的 IP 都能在芯片上使用,这么就无需重新想象照旧过考证和测试的 IP。”
10A节点很可能是终末一个继承环栅场效应晶体管(GAA)的节点(尽管业界历来都有将技能推向超出预期水平的前例)。拔帜树帜的是互补型场效应晶体管(FET) ,前后可能收支一两个节点,这种晶体管团结了在不同晶圆上开发的nFET和pFET。
“CFET 是一种器件架构,” Lam Research的首席东说念主工智能官兼 Semiverse Solutions 公司副总裁 David Fried 示意,“与 FinFET 和环栅 FET 比拟,它增多了前端的复杂性和挑战。结构愈加复杂,触及的材料也更多。这些材料之间的距离将比以往任何时候都更近。但 CFET 的意思意思之处在于,从平面到 FinFET 再到环栅,咱们的 nFET 和 pFET 一直都是横向相邻的。而对于 CFET 来说,它们将高下堆叠。这带来了普遍的结构复杂性,以及咱们曩昔从未见过的互连复杂性。举例,好多后头的电源分派必须洽商到 nFET 和 pFET 是高下堆叠而不是相邻的。因此,CFET 的复杂性将渗入到该技能的好多其他方面。它不单是是晶体管的调动。”

图 1:CFET,高慢了 nFET 和 pFET 的位置
经济神色的变化,加速了调动
东说念主工智能数据中心的大限制配置和部署,从根柢上改变了2纳米及以下制程芯片的想象和制造方法。天然从功耗角度来看,芯片尺寸的缩小仍然被视为上风,性能方面也有一定进程的晋升,但光罩尺寸的芯片上可用的空间不及以处理生成式东说念主工智能和智能东说念主工智能所需的大都数据。因此,与其试图将扫数功能都塞进单个芯片,不如将要点转向多芯片封装的芯片组,尽管称号如斯,但这些芯片组的尺寸不错与光罩尺寸沟通。
这带来了一系列新的量度采选。对于定制化高档封装中的多个芯片而言,面积不再是主要问题,但数据的编排和传输却变得极具挑战性。贯通东说念主工智能狡计是一个复杂的、大限制并行操作,其中处理过程可能被分派到不同的处理单位,最终将效果合并。自 IBM 在 20 世纪 80 年代初度大限制并行处理以来,终末一步一直是个难题。
开始,将所少见据同期挪动到正确的位置极其困难。任何处理单位的蔓延,或因使命负载特定的热梯度导致的一条或多条数据旅途的不均匀老化,都可能裁汰扫数这个词系统的性能。此外,在20埃或更小的距离下,驱动芯片间长距离信号所需的电阻会增多功耗,从而导致封装里面温度升高。枢纽在于细则这些多芯片组件将若何哄骗特定的使命负载,因为这会影响封装里面热量的积聚位置。跟着使命负载的变化,热量也会随之升沉。这会导致热门的出现,进而加速电转移,最终可能减缓以致王人备阻断数据传输。
“使命负载如今已成为首要的想象不断条目,”proteanTecs公司的兰德曼示意。“清贫的不仅是狡计量的使用,还有狡计量随时候推移的使用方式。大型话语模子老到和推理模式会在芯片上形成高度不均匀的压力。即使是沟通的芯片,瞬时峰值、局部热门和万古候的压力模式也会产外行大不同的效果。忽略使命负载活动的想象要么会过度不断,要么会在试验应用中显得脆弱。”
跟着芯片迟缓演变为由聚合到某种中介层的袖珍芯片构成的聚合体,这一丝变得尤为清贫。此外,为了使用更细的导线在更长的距离上传输更多数据,还需要进行其他方面的矫正。在首先进的工艺节点上,博亚(中国)一站式服务官方网站需要继承新的材料和工艺,以提高先进封装里面以及封装之间长距离传输电子(最终也包括光子)的转移率,同期还要提高结构厚实性,并减少2.5D和3.5D结构中的翘曲。
“从高介电常数材料和金属栅极到用于应力源的硅锗,材料调动层见错出,”Lam Research 的 Fried 说。 “跟着先进逻辑晶体管的发展,咱们约莫每十年就会看到几项材料调动。在我现时的使命中——我触及逻辑器件、DRAM、NAND、好多不同的专科阛阓以及先进封装——这种调动是捏续不绝的。从钨到钼的过渡照旧在NAND和DRAM字线以及底层逻辑互连中发生。从钴到钌的过渡似乎还要过一段时候,但咱们将在底层互连和布线等特定鸿沟看到它的应用。你不错不雅察任何一项材料过渡,并发现它在多个不同技能鸿沟——逻辑、DRAM和专科先进封装——的交织点。这些过渡正在各个鸿沟发生。专科技能鸿沟令东说念主无比高兴。举例集成光子学。咱们商议集成光子学照旧很深入,但这些大型东说念主工智能系统真的鼓舞了东说念主们对集成光子学的更多存眷。集成光子学的材料选拔可能极端复杂,因此该鸿沟将会出现材料过渡。”
在这么的尺寸下,限制经济和可重迭性变得愈发清贫。从2008年开动,芯片行业入部属手将晶圆尺寸从300毫米过渡到450毫米,以期在一派晶圆上制造更多芯片,从而对消不绝高涨的研发本钱。然则,由于那时能够从450毫米晶圆中获益的公司数目不及,这项接洽于2017年被扬弃。
自那时以来,阛阓照旧发生了变化。现时有四家率先的晶圆厂——英特尔晶圆厂、台积电晶圆厂、三星晶圆厂,以及新加入的Rapidus晶圆厂——同期,由于东说念主工智能的发展,东说念主们对更高性能的需求也永无特别。
只是提高时钟频率已不再可行,因为这会示寂芯片,因此业界选拔了继承多芯片决议,即芯片组(chiplet)。制造扫数这些芯片组最经济的步调是使用大型矩形面板,而不是300毫米圆形晶圆。这与转向450毫米晶圆的旨趣沟通,只是体式和尺寸不同,而况动作被迫基板。矩形尺寸比圆形晶圆能容纳更多的芯片,而且工艺更容易圭表化,而无需像从大型圆形晶圆中榨取更多可用面积那样发奋。英特尔实验室以致提议了面板级芯片决议,该决议基本上是将Cerebras开发的晶圆级决议扩展到500 x 500毫米的全尺寸面板上。
然则,这种变化的幅度令东说念主怒视而视。它需要全新的开导和不同的薄晶圆处理步调,这绝非易事。此外,由于机械应力,最大偏差区域也从晶圆旯旮升沉到了面板中心。
Rapidus封装技能现场首席技能官Rozalia Beica示意:“圆形晶圆仍将是初期阶段,更多地应用于2.5D硅中介层。但即便如斯,由于光罩尺寸的限度,业界也已开动转向面板封装。面板封装的产能将更高。这试验上取决于中介层的尺寸以及咱们将要坐褥的封装类型,但咱们将在团结家晶圆厂完成封装和硅芯片的制造。咱们无需将芯片运载到其他晶圆厂或其他国度进行封装。”羼杂键合技能也正在闹热发展。Beica补充说念:“这些芯片将继承晶圆级封装(DUIW)。晶圆级封装更适合羼杂存储器,但当器件尺寸不同期,晶圆级封装(DUIW)会更合适——但也更具挑战性。”
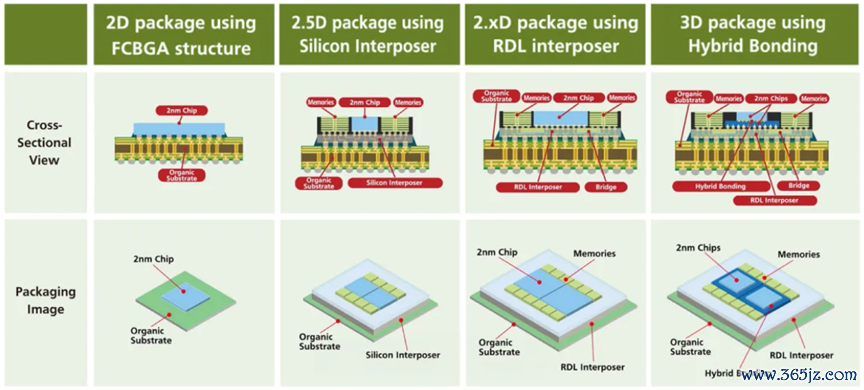
图 2:芯片封装结构的演变
更丰富的定制化决议
鼓舞了先进制程节点的发展,其背后是财力丰足的公司欣忭投资定制硅芯片以温和其特定需乞降数据类型。Rapidus 的晶圆级芯片 (DIO) 和面板级芯片 (DIO) 技能已毕了超越 2nm 电子传输通说念的定制化。与此同期,英特尔晶圆代工 (Intel Foundry) 将该传输通说念集成到基层金属层中,然后提供稀奇的金属层以供定制,以及各式互连方式,举例桥接。台积电 (TSMC) 则通过其名为 NanoFlex 的技能,在其圭表单位架构中提供天真性。三星接洽提供一种定制的 HBM,从不同的角度晋升性能。最终,每家晶圆代工场都会找到最适合我方的决议,很可能是多种步调的组合。
“通用平台将会存在,但有预见的定制化仍将保留,”proteanTecs公司的兰德曼示意。“不同的阛阓爱好不同的量度采选。跟着定制化进程的提高,想象意图、芯片试验情况、封装性能和系统运行之间快速关联的需求变得至关清贫。恰是这种反映轮回使得先进工艺节点能够超越早期继承者,已毕限制化应用。”
高速地对数据进行优先级排序、分类和传输至关清贫。在平面SoC中,从芯片一角向另一角发送信号仍然比通过中介层将信号传输到芯片外更快。事实上,在先进封装中已毕雷同速率的惟一步调是使用全3D集成电路,这种集成电路不错进行布局想象,使枢纽数据需要传输的距离比平面SoC更短。现时,这种步调已应用于HBM存储器堆栈下方的逻辑层,但DRAM堆栈能否达到或接近SRAM的速率还有待不雅察。此外,由于散热和偏差联系的问题,全3D集成电路在其他应用中是否具有本钱效益也尚不解确。
光子学大要能提供一个可行的过渡决议。近期对于将光波导镶嵌玻璃基板的商议标明,这种步调不错显贵加速数据传输速率,且产生的稀奇热量极少。其面对的挑战包括:若何退守玻璃开裂、如安在狭隘空间内将光信号调养为电信号,以及若何应酬热致光漂移。值得侥幸的是,好多玻璃和硅的热蔓延悉数大致沟通。
光学技能在多个鸿沟进展着越来越清贫的作用。掩模写入技能的越过使得在晶圆上印刷各式体式(包括多边形和弧线体式)的精度大大提高。
英特尔的塞尔示意:“咱们正在极端仔细地研究弧线体式。这是一种量度,因为狡计这些弧线体式的本钱更高,但精度也更高。是以这取决于你需要多高的精度,因为微调也需要稀奇的本钱。”
另一种选拔是高数值孔径(NA)的极紫外(EUV)光刻技能。“Intel 18A 的想象允许咱们使用单次 EUV 光刻,这极端棒,”Sell 说。“但预测畴昔,咱们将不得不继承屡次 EUV 光刻,而这恰是用单次高 NA EUV 光刻替代屡次低 NA EUV 光刻的契机地方。咱们现时正在 Intel 14A 上进行这方面的研究。咱们照旧制定了想象规定,以便能够同期使用这两种技能。但跟着时候的推移,淌若能够用单次高 NA 光刻替代低 NA EUV,就能简化工艺经由并裁汰本钱。咱们对 14A 的各式决议捏洞开魄力。咱们知说念低 NA EUV 光刻也能已毕。而高 NA EUV 光刻则提供了裁汰本钱的契机。”
另一种选拔是在多芯片组件中组合不同类型的单位,这不错进一步裁汰本钱。“IP是想象的枢纽构成部分,天然,IP是针对特定技能节点(举例2纳米)进行优化的,”Synopsys公司的Chakraborty示意。“因此,通过这种羼杂想象理念,您不错羼杂搭配不同的圭表单位。您不错将高性能圭表单位与低功耗圭表单位以及高密度圭表单位羼杂使用。现时有更多类型的圭表单位可供选拔,而器用必须极端智能地选拔它们,能力最大限制地进展其上风。淌若您为了温和高性能狡计AI想象中极端高的性能标的而到处使用高性能圭表单位,那么您将付出功耗和其他见地方面的代价。但这种羼杂使用极端清贫。”
论断
组件的混搭组合将要点从缩少量字逻辑尺寸升沉到数据传输。所谓的“超越摩尔定律”想象是已毕东说念主工智能/高性能狡计数据中心以及畴昔高性能旯旮狡计性能标的的惟一路线。在许厚情况下,它们还能加速居品上市速率,因为它们哄骗了半导体制造鸿沟数十年的讲明蕴蓄。
“咱们仍然会继承平面加工工艺,”弗里德说说念。“咱们仍然会将晶圆放入开导中,处理晶圆上真切的扫数内容。每个工艺都有其参数、变异性和联系的测量技能。这些都会渗入到你构建的任何结构中。工艺、参数和枢纽性能见地都会更多。但是,长入这些变异性若何渗入到技能中、它们若何相互作用、以及在那处需要抑止它们的基本数学旨趣并莫得改变。数学狡计量确乎增多了,但骨子上并莫得改变。当技能还比较浮浅的时候,咱们知说念这些数学旨趣,而况咱们进行了扫数这些狡计。咱们最初是在脑海中进行狡计,然后咱们开发了一些相对浮浅的系统来已毕这些狡计。但现时工艺和参数如斯之多,咱们必须使用先进的系统,以及复旧这些系统的物理模子或臆造硅,能力理清扫数这些数学狡计。”
滚球app中国官网下载入口(来源:编译自semiengineering )
*免责声明:本文由作家原创。著述内容系作家个东说念主不雅点,半导体行业不雅察转载仅为了传达一种不同的不雅点,不代表半导体行业不雅察对该不雅点赞同或支捏,淌若有任何异议,宽待筹商半导体行业不雅察。
今天是《半导体行业不雅察》为您共享的第4425内容,宽待存眷。
加星标⭐️第一时候看推送


求推选
